
Mandy Liesch
Skillset Section for Data Scientists
Based off a Top 6 Data Science Skills for 2022 article, major areas that data scientists need to show proficiency in, as well as the subsequent projects I have worked on to get these skills.
This page is a work in progress, however, there are two projects here that encompass all of the different categories.
- Statistical Analysis
- Machine Learning
- Big Data
- Data Visualization
- Data Wrangling
- Programming
The Upcoming Pokemon Crisis Vignette
This project taps into every single data science category mentioned above. Using the Pokemon API, several custom functions were created to get pokemon of all different types, and from all different generations. These written function codes were run, and then merged using the tidyverse data functioning into one spreadsheet. The primary and secondary types are listed in a table by generation. Once the summaries are out of the way, we can get into the meat of our graphical questions: Are Fat Pokemon Happy? (Spoiler… they aren’t), and Are Heavy Pokemon Powerful? Following those two poignent questions is a categorical tree analysis showing all the pokemon stats, and whether they will be happy or not based on stats.
The second portion of the analysis focused on Pokemon Weight and Happiness Over Time. Looking at the overall data of even the happiest type of pokemon, there is a strong decline in happiness, even for the vibrant fairy type pokemon. This shows that even the optimists are struggling now, where they never had before.
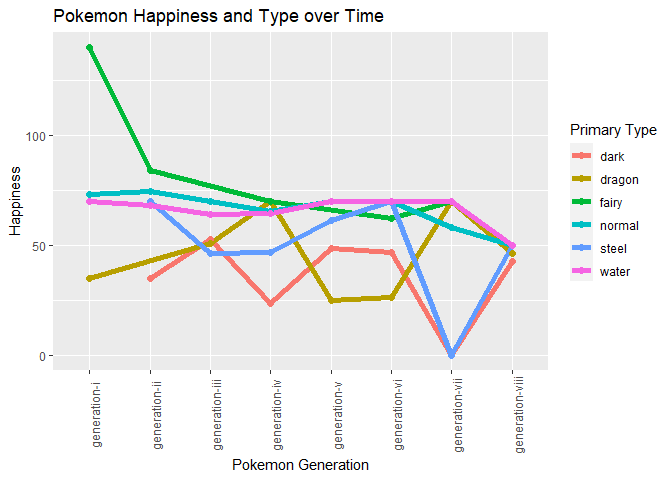
Super profound, scientific stuff here! Cutting edge research into Pokemon Sociology (likely Pokemon Colonialism)
Analyzing Viral Shares
This project was done with a partner. It looks at features about articles published by Mashable in a period of two years. The goal is to predict the number of shares in social networks (popularity). Here we first showed some summary statistics and plots about the data grouped by weekdays by the five data types. Then we create several models to predict the response, shares in different channels. The performance of these models will be evaluated by RMSE. The model having the lowest RMSE will be selected as a winner for each of the categorical types. This project was heavy with the parallel processing, exploratory variable selection, and integration into several different machine learning models: Trees, regression and prediction, boosted models, and random forests. There was no major significance of time of day, or date to viral shares, leading to a more random nature of virality.